前回は、箱庭PDUの責務分離と設計上の境界、
そして実装レベルでのデータの流れについて説明しました。
じつは、これまで箱庭PDUについては、
「ここまで用意するので、あとはお好きに実装してください」
というスタンスを取ってきました。
具体的には、PDUの定義やデータ変換、通信プロトコルの選択については、
箱庭として最低限のデフォルトツール
(データ型変換、バイナリ変換)は用意していましたが、
基本的にはユーザの自由度を最優先する方針を貫いてきました。
自分がツラくなってきました。
そんなカッコイイことを言っておきながら、
いざ Runtime Delegation の実装を本気で考え始めると、
一番ツラくなったのは、他でもない自分自身だったのです。
自由度を高く保つ、という判断そのものは間違っていませんでした。
しかし、その自由度を前提にしたまま、
実装を進めるには限界があることも、はっきりしてきました。
そして。
Runtime Delegation の概念モデルをいろいろと検討していく中で、
どうしても、
PDUの入出力を概念どおりに扱える、
それこそ設定(config)一つで切り替えられる、
そんな通信の「単点(endpoint)」が必要だ、
と気づいたのです。
この「通信の単点」を、明示的な概念として切り出したものが、hakoniwa-pdu-endpoint
です。
こちらで、その実装を一般公開しています。(まだ変わるかもしれませんが。)
クラス設計もやった。
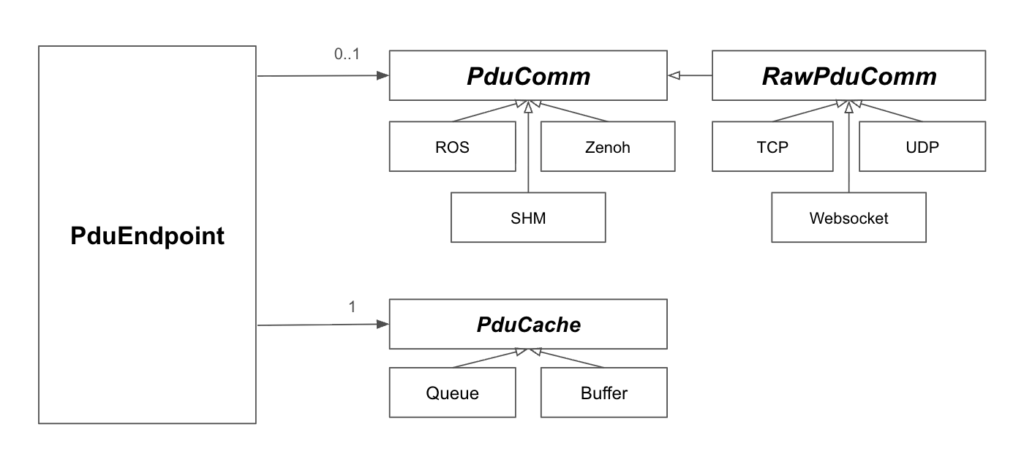
さて、次はクラス設計の話です。
ここでは、先ほどの図をもとに、PduEndpoint の中身を説明します。
この設計に至るまでに、自分の中で大きな気づきがありました。
最初は「通信」しか見ていなかった
最初に考えていたのは、正直なところ 通信 だけでした。
PDUをどう送るか。
TCPか、UDPか、ROSか、Zenohか。
送信については、それで問題ありません。
しかし、実装を進めるうちに、すぐに気づいたのです。
受信したデータ、どこに置くんだ?
受信は必ず「溜まる」
受信したPDUは、その場で必ず処理できるとは限りません。
つまり、どこかに保持する必要がある。
この「保持」をどう扱うかを考えている中で、
ChatGPT との対話も含めて整理していくうちに、
この問題は単なる受信処理ではなく、
キャッシュ(cache)の問題として捉えるのが自然だと気づきました。
こうして生まれたのが PduCache です。
PduCache:Queue と Buffer という選択肢
PduCache は、受信したPDUを一時的に保持するための仕組みです。
そして、その実装として、複数の選択肢を持たせました。
- Queue
- FIFOでPDUを保持
- キュー長制御が可能
- 非同期処理と相性が良い
- Buffer
- 最新データで上書き
- 状態保持用途に向いている
- 実装がシンプル
用途に応じて、
「溜めたいのか」「最新だけでいいのか」
を選べるようになっています。
通信の違いは想像以上に大きい
もう一つ大きな分岐点がありました。
通信方式には、大きく2種類あります。
- Zenoh / ROS
- トピックのような上位概念を持つ通信
- PDU単位でのやり取りが前提
- TCP / UDP
- コネクションを張って直接I/O
- バイト列の送受信が基本
この違いは、単なる実装差では済みません。
抽象度がまったく違うのです。
RawPduComm の役割
この差を吸収するために導入したのが RawPduComm です。
RawPduComm は、
- TCP / UDP / WebSocket のような
- 「バイト列しか扱えない通信」
を、PDUという上位概念に引き上げるための層です。
そのため、RawPduComm は PduComm を継承しています。
外から見ると、
- ROS でも
- Zenoh でも
- TCP / UDP でも
すべて PduComm として扱える。
これが、この設計の肝です。
PduEndpoint は「組み合わせの起点」
最終的に、PduEndpoint は次のような役割を持ちます。
- 通信するか、キャッシュするかを選ぶ
- 通信する場合は、PduComm / RawPduComm を切り替える
- 受信したPDUは、PduCache に流す
PduEndpoint 自体は、
- 通信方式の違い
- キューかバッファか
- 実装の細部
を知りません。
ただ、組み合わせるだけです。
この設計で得られたもの
この構造にしたことで、
- 通信方式の追加が楽になる
- 受信処理の整理が一気に進む
- Runtime Delegation のような複雑な要件にも耐えられる
土台ができました。
ちなみに、PduComm の実装としては、
必ずしも「ネットワーク通信」である必要はありません。
たとえば、
- デバッグ出力
- 受信した PDU をそのままログに吐く
- ストレージ保存
- PDU をファイルやDBに書き出す
- テスト用ダミー実装
- 通信せずに PDU を注入・回収する
といったものも、
PduComm の一実装として自然に組み込めます。
ここで重要なのは
PduEndpoint から見ると、
それが「どこに送られているか」は問題ではない
という点です。
- ネットワークか
- ローカルか
- デバッグか
- 永続化か
PduEndpoint はそれを知りません。
ただ 「PDUを出す先」 を切り替えているだけです。
最後に。
ここまで細かく説明してきましたが、
実際にユーザが触るのは、もっとシンプルです。
これが PDU エンドポイントの定義です。
箱庭では、これを JSON ファイルで記述します。
endpoint.json
{
"name": "tcp_server_buffer_endpoint",
"cache": "cache/buffer.json",
"comm": "comm/tcp_server_inout_comm.json"
}cache/buffer.json
{
"type": "buffer",
"name": "default_latest_buffer",
"store": {
"mode": "latest"
}
}comm/tcp_server_inout_comm.json
{
"protocol": "tcp",
"name": "tcp_server_inout",
"direction": "inout",
"role": "server",
"local": {
"address": "0.0.0.0",
"port": 54001
},
"options": {
"read_timeout_ms": 1000,
"write_timeout_ms": 1000
}
}重要なのは、これらの JSON が 通信処理の実装を一切含んでいない ことです。
- TCP の socket API は出てこない
- send / recv の話も出てこない
- キューかバッファかという「方式」は指定しているが、
その内部実装は、ここでは意識する必要がありません
これらの設定は、
箱庭PDUにおける一つの「端点(endpoint)」を
定義しているに過ぎないのです。
いやー、これは、われながら、
「楽しい!」
つづく。
コメントを残す